Spark Streaming/SQL/MLlib/GraphX
Spark 这一大数据分析框架,包含了:
- 流计算: Streaming
- 图计算: GraphX
- 数据挖掘: MLlib
- SQL
Spark Streaming
参考: http://spark.apache.org/docs/latest/streaming-programming-guide.html

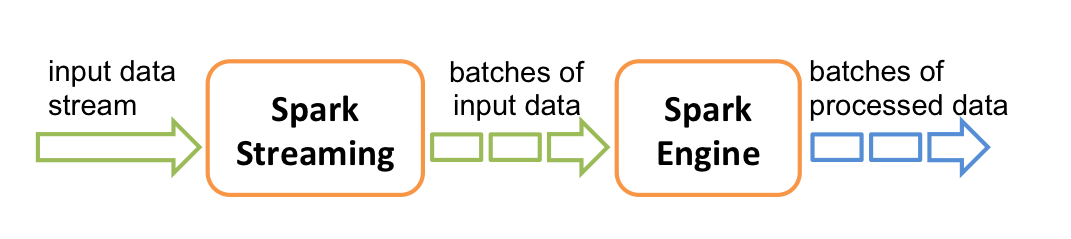
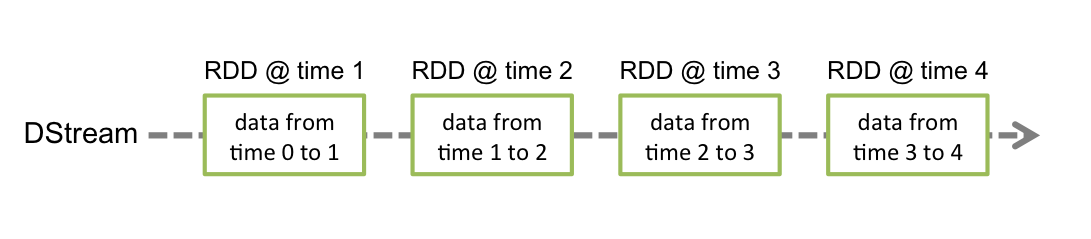
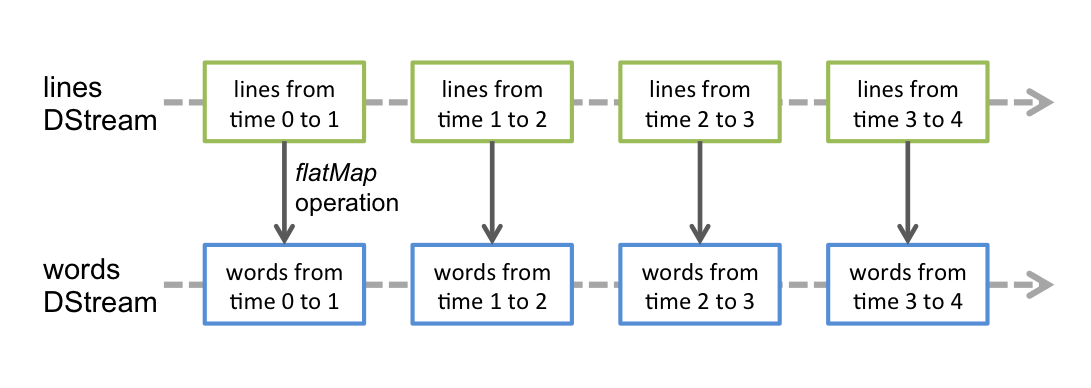
Spark Streaming Example
StreamingContext:
1 2 3 4 5 6 7
| import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1))
|
socket:
1 2 3 4 5 6 7 8 9 10 11 12
| val lines = ssc.socketTextStream("localhost", 9999) val words = lines.flatMap(_.split(" ")) import org.apache.spark.streaming.StreamingContext._ val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination()
|
往9999端口里面输入:
1 2
| $ nc -lk 9999 $ ./bin/run-example streaming.NetworkWordCount localhost 9999
|
Spark GraphX
参考: http://spark.apache.org/docs/latest/graphx-programming-guide.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD class VertexProperty() case class UserProperty(val name: String) extends VertexProperty case class ProductProperty(val name: String, val price: Double) extends VertexProperty var graph: Graph[VertexProperty, String] = null class Graph[VD, ED] { val vertices: VertexRDD[VD] val edges: EdgeRDD[ED] }
|
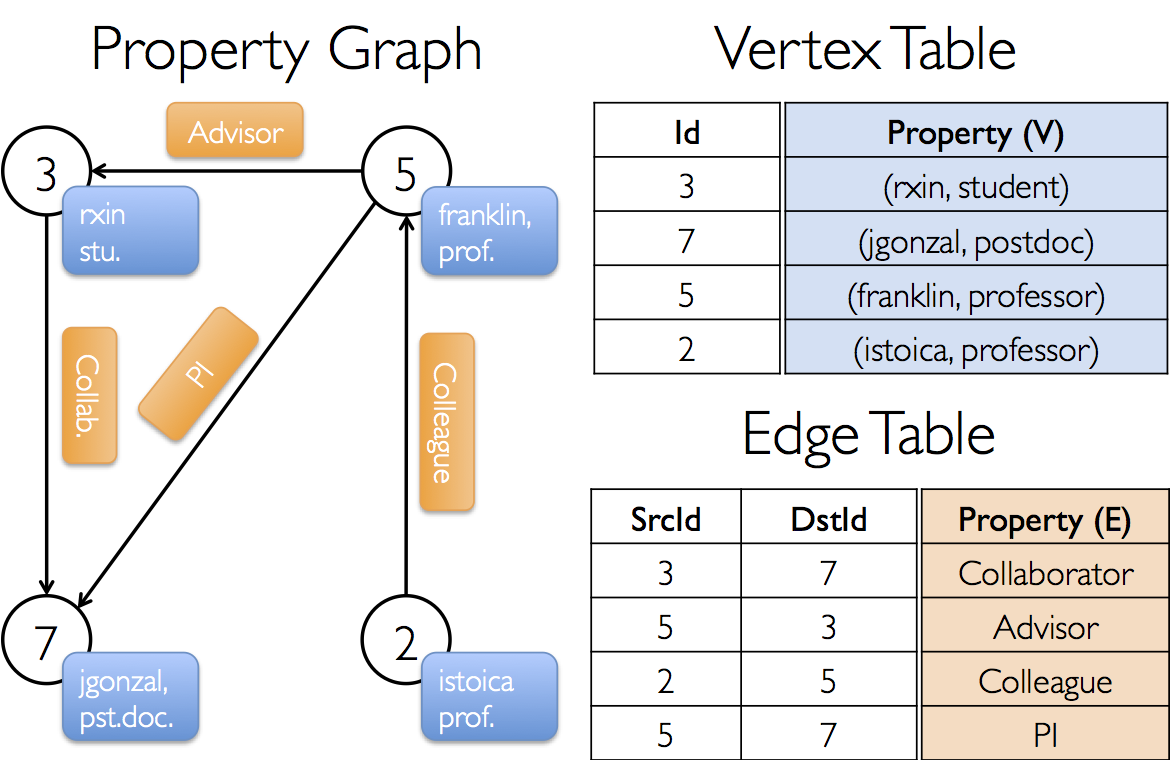
构建graph的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| val userGraph: Graph[(String, String), String] val sc: SparkContext val users: RDD[(VertexId, (String, String))] = sc.parallelize(Array((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")), (5L, ("franklin", "prof")), (2L, ("istoica", "prof")))) val relationships: RDD[Edge[String]] = sc.parallelize(Array(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"), Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi"))) val defaultUser = ("John Doe", "Missing") val graph = Graph(users, relationships, defaultUser) val graph: Graph[(String, String), String] graph.vertices.filter { case (id, (name, pos)) => pos == "postdoc" }.count graph.edges.filter(e => e.srcId > e.dstId).count graph.edges.filter { case Edge(src, dst, prop) => src > dst }.count val graph: Graph[(String, String), String] val facts: RDD[String] = graph.triplets.map(triplet => triplet.srcAttr._1 + " is the " + triplet.attr + " of " + triplet.dstAttr._1) facts.collect.foreach(println(_))
|
Graph Operators:
1 2 3
| val graph: Graph[(String, String), String] val inDegrees: VertexRDD[Int] = graph.inDegrees
|
Shortest Path:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| import org.apache.spark.graphx.{Graph, VertexId} import org.apache.spark.graphx.util.GraphGenerators val graph: Graph[Long, Double] = GraphGenerators.logNormalGraph(sc, numVertices = 100).mapEdges(e => e.attr.toDouble) val sourceId: VertexId = 42 val initialGraph = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity) val sssp = initialGraph.pregel(Double.PositiveInfinity)( (id, dist, newDist) => math.min(dist, newDist), triplet => { if (triplet.srcAttr + triplet.attr < triplet.dstAttr) { Iterator((triplet.dstId, triplet.srcAttr + triplet.attr)) } else { Iterator.empty } }, (a, b) => math.min(a, b) ) println(sssp.vertices.collect.mkString("\n"))
|
Spark SQL
参考: http://spark.apache.org/docs/latest/sql-programming-guide.html
1 2 3 4 5 6 7
| val jdbcDF = spark.read .format("jdbc") .option("url", "jdbc:postgresql:dbserver") .option("dbtable", "schema.tablename") .option("user", "username") .option("password", "password") .load()
|
Running the Thrift JDBC/ODBC server:
1 2 3 4 5 6
| ./sbin/start-thriftserver.sh export HIVE_SERVER2_THRIFT_PORT=<listening-port> export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host> ./sbin/start-thriftserver.sh \ --master <master-uri> \ ...
|
Running the Spark SQL CLI:
Spark MLlib
参考: http://spark.apache.org/docs/latest/ml-guide.html
